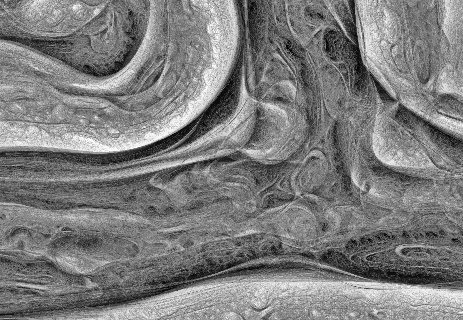
Surfing the web a beautiful, pencil-drawn like image captured my attention, it looked like as a hand-drawn image, but also became almost evident that it was a computer generated art. I found that it was created using an algorithm known as Coherent Line Drawing.

Introduction
In the last period of time I have been working on and off (as my limited free time permitted) on the implementation of the Coherent Line Drawing algorithm developed by Kang et al. Only now I considered that the implementation is so stable that I can publish it, so here it is: https://github.com/esimov/colidr.
Since my language of choice was Go I decided to give it a try implementing the original paper in Go, more explicitly in GoCV, an OpenCV wrapper for Go. I opted for this choice since the implementation is heavily based on linear algebra concepts and requires to work with matrices and vector spaces, things in what OpenCV notoriously excels.
However some of the functions required by the algorithm were missing from the GoCV codebase (at that period of time) like Sobel, uniformly-distributed random numbers and also vector operations like getting and setting the vector values. Meantime checking the latest release I found that the core codebase has been extended with some of the missing functionalities like the Sobel threshold, bitwise operations etc., however there were still missing pieces required by the algorithm. For this reason I have extended the GoCV code base with the missing OpenCV functionalities and included into the project as vendor dependency. Probably in the upcoming future I will create a pull request to merge it back in the main repository.
I won’t go into too much detail about the algorithm itself, you can find it in the original paper. I will discuss mostly about the technical difficulties encountered during the implementation, but also about the challenges imposed by gocv and OpenCV.
Why Go?
Now let’s talk about the challenges imposed by the project. The first question which might arise is why in Go, knowing that Go is not really appealing for creative coding, and it is mostly used in automatization, infrastructure, devops and web programming.
From my first acquaintance with Go (which was quite a few years back) I was intrigued by the potential possibilities offered by the language to make use of it in fields like image processing, computer vision, creative coding etc, since these are the fields i’m mostly interested in, and almost all of my open source project developed in Go have circulated around this topic. So this project was another attempt of mine to demonstrate that the language is well suited for these kind of projects too.
Go has a small package for image operations, but it is fair enough for anything you need to read an image file, obtain and manipulate the pixel values and finally to encode the result into an output file. Everything is concise and well structured. Since in this project we mostly rely on the OpenCV embedded functions provided by GoCV, there are still plenty of use cases when you need to rely on the core image library. Go does not provide a high level, abstract function to modify the source image, you need to access the raw pixel values in order to modify them.
Another key aspect in the language choice was that Go has an out of the box command line flag parsing library, just what I needed, since I conceived this application to be executed from the terminal. Maybe in the upcoming future I will create a GUI version too.
Technical challenges
Going back to the technical challenges I encountered during the implementation, one of the main headaches was related to how sensible OpenCV is to the way the types of matrices are declared. I was banging my head into the wall many times for the simple reason that my matrices were defined as gocv.MatTypeCV32F, however they should have been defined as gocv.MatTypeCV32F+gocv.MatChannels3, since the concatenation of these two variables were producing the desired matrix type value declared in the underlying OpenCV code base. More exactly by creating a new Mat and defining it’s type as simply MatTypeCV32F, the underlying gocv method will call the Mat_NewWithSize C method, having the last parameter the type of the matrix. Exactly this kind of limitation have confused me, ie. not all of the supported OpenCV mat types have been defined in the GoCV counterpart.
Since OpenCV is very flexible on matrix operations and won’t complain about the matrix conversions from one type to another, there are some edge cases when they are producing undesired results. This is a thing you have to consider when you are doing matrix operations in OpenCV: you need to be aware of the matrix type, otherwise your end results could be utterly compromised.
However comparing the OpenCV and GoCV matrix type tables, a lot of types are still missing from GoCV. For this simple “thing” my outputs were far from desirable from what it should have been. I was spinning in round and round, going back and forth, trying different solutions, comparing the code with the pseudo algorithms and formulas provided in the original paper to finally realizing that my matrices were defined with the wrong type or because some of the types declared in OpenCV were completely missing from the GoCV counterpart. The solution was either to extend the core code base or to concatenate the two matrix types (as presented above) in order to produce the correct type value requested by OpenCV.
Another elementary thing which is missing from GoCV is the SetVecAt method for setting or updating the vector values, even though a method for retrieving the vector values does exists. My initial attempt was to modify the vector values on byte level and encode it back into a matrix using the GoCV NewMatFromBytes method, which proved to be completely inefficient.
The solution was to extend the core GoCV codebase with a SetVec method.
Another thing I learned is converting one matrix type to another does not always work as you think. I experienced this issue when during the debugging session I had to convert a float64 matrix to uint8, which can be exported as a byte array needed for the final binary encoding. It worked, but converting back to a float64 matrix requested by rotateFlow method didn’t not produced the desired output. (This method applies a rotation angle on the original gradient field and calculates the new angles.)
Since Go is using strict types for variable declarations, the auto casting is not possible like in C or C++. For this reason you need to pay attention to how you are converting the values from one type to another. Because GoCV / OpenCV matrices defined as floats are using 32 bits precision float values we need to be cautious when we have to cast a value defined as float64 for example to a 32 bit integer. This was the case on edge tangent flow visualization.
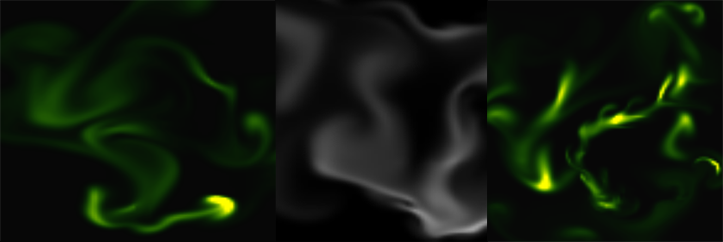
The examples below were produced with the wrong (left) and good type casting (right).


Even though the paper provided the implementation details for ETF visualization, my first attempt of it’s implementation didn’t produced the correct results. Only when I printed out the results I realized that the values were spanning over the range of the 32 bit integers, however OpenCV does not complained about this. The solution for this problem was to cast the index values of the for loop iterator as float32.
This is a takeaway you have to consider when you are working with OpenCV matrix types, especially in a language like Go, which is very strict in terms of variable types definition.
Conclusion
To sum up: GoCV is a welcome addition for the Go ecosystem, considering that it is under development many of the core OpenCV features are already implemented. However as I mentioned above there are still missing features, which should be addressed to become a viable OpenCV wrapper for the Go ecosystem. What I have learned using OpenCV is that you have to tinker with the values, and slight changes on the inputs can produce completely broken outputs, so you need to find that tiny middle road where the different equation parameters can converge.
Sample images








Source code
The code is open source and can be found on my Github page:
https://github.com/esimov/colidr
You can follow me on twitter too: https://twitter.com/simo_endre